
DeepSWE, created by DataCurve offers a benchmark for assessing AI coding models by focusing on real-world programming challenges rather than synthetic test cases. According to Matthew Berman, one of its defining features is the use of contamination-free tasks, carefully curated to ensure models are not exposed to problems they may have encountered during training. These tasks are drawn from 91 open source repositories spanning languages such as TypeScript, Go and Rust, providing a diverse and practical evaluation of how coding models handle different programming paradigms. The framework also incorporates a rigorous verification system to reduce errors and deliver consistent performance metrics.
Dive into how DeepSWE evaluates coding models on practical tasks, emphasizing behavioral accuracy and resource efficiency. Learn how GPT 5.5 balances speed, cost and accuracy while outperforming models like Opus 4.7 in runtime and expense. Understand the difficulties faced by models such as Claude Haiku 4.5 when dealing with multi-part prompts and examine how DeepSWE facilitates meaningful comparisons across AI coding systems.
The Importance of Contamination-Free Tasks
TL;DR Key Takeaways :
- DeepSWE is a new AI coding model benchmark that focuses on real-world coding challenges, making sure tasks are contamination-free, original and unbiased.
- It evaluates models across 91 diverse open source repositories in five programming languages (TypeScript, Go, Python, JavaScript, Rust), reflecting real-world complexity and varied use cases.
- DeepSWE emphasizes practical problem-solving with concise prompts and high token requirements, aligning closely with real-world developer challenges.
- Verification mechanisms ensure reliable results with exceptionally low error rates (0.3% false positives, 1.1% false negatives), providing accurate insights into model performance.
- GPT 5.5 leads in performance, balancing accuracy, cost-efficiency and speed, while other models like Opus 4.7 and Claude Haiku 4.5 highlight areas for improvement.
DeepSWE introduces entirely original, handcrafted tasks to ensure unbiased evaluation. By avoiding reliance on public datasets like GitHub commits or issues, it guarantees that AI models are tested on problems they have not encountered during training. This eliminates data contamination, allowing for a more accurate assessment of a model’s true problem-solving abilities. The emphasis on originality ensures a level playing field, making DeepSWE a reliable tool for evaluating AI coding models.
Diverse Repositories for Comprehensive Testing
To reflect the complexity of real-world coding, DeepSWE spans 91 active open source repositories across five programming languages:
- TypeScript
- Go
- Python
- JavaScript
- Rust
This diversity mirrors a wide range of coding scenarios, from web development to system-level programming. By incorporating varied architectures and use cases, DeepSWE evaluates how well models adapt to different programming paradigms and challenges. This comprehensive approach ensures that models are tested on tasks that closely resemble the challenges faced by developers in their daily work.
Advance your skills in AI benchmarks by reading more of our detailed content.
Real-World Complexity: A Benchmark for Practical Skills
DeepSWE’s tasks are designed to simulate real-world developer interactions with coding agents. The prompts are concise, requiring models to infer and implement solutions with minimal guidance. Unlike other benchmarks, DeepSWE demands significantly more code and output tokens, pushing models to tackle complex, practical problems. This ensures that the benchmark aligns closely with the challenges developers encounter, making it a true test of an AI model’s practical capabilities.
Reliable Verification for Accurate Insights
Verification is a cornerstone of DeepSWE’s reliability. Its robust mechanisms reward correctness across various valid implementations, achieving exceptionally low error rates—0.3% for false positives and 1.1% for false negatives. Compared to benchmarks like SWEbench Pro, DeepSWE offers a more precise assessment, providing actionable insights into model performance. This level of accuracy ensures that developers and researchers can trust the results when comparing different AI coding models.
Performance Insights: GPT 5.5 Leads the Pack
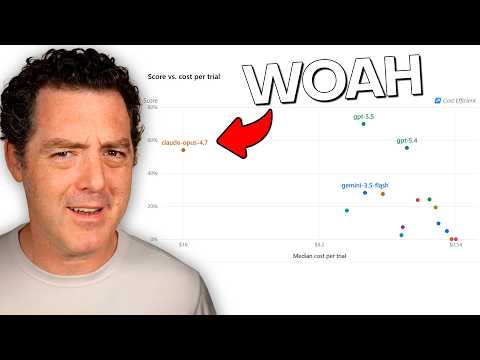
DeepSWE’s evaluations reveal clear distinctions in performance among AI coding models. GPT 5.5 emerges as the top performer, achieving 70% accuracy while maintaining cost-efficiency and fast execution times. In contrast, Opus 4.7, though competitive in accuracy, is less efficient and significantly more expensive. Other models, such as Gemini 3.5 Flash and Claude Haiku 4.5, show notable performance gaps, highlighting areas for improvement. These results provide a detailed understanding of how each model performs under real-world conditions.
Behavioral Insights: Strengths and Weaknesses
DeepSWE offers valuable insights into the behavioral tendencies of AI coding models:
- GPT 5.5: Excels in adhering to prompts, producing accurate and efficient solutions.
- Opus 4.7: Demonstrates strong environmental awareness but struggles with cost-efficiency and speed.
- Claude Haiku 4.5: Struggles with multi-part prompts and parallel tasks, highlighting the need for refinement.
These observations help developers identify where models excel and where they fall short, guiding future improvements and optimizations.
Balancing Cost and Efficiency
DeepSWE emphasizes the importance of balancing performance with resource efficiency. GPT 5.5 stands out as the most balanced model, offering the best combination of accuracy, cost and speed. At $5.80 per trial and an average runtime of 20 minutes, it outperforms competitors like Opus 4.7, which is three times more expensive and slower. Additionally, GPT 5.5 generates concise, effective solutions, with a lower median output token count than its peers. This focus on efficiency ensures that DeepSWE evaluates models in a way that aligns with the practical needs of developers.
Innovative Features of DeepSWE
DeepSWE introduces several innovations that distinguish it from existing benchmarks:
- End-to-End Exploration: Tasks encourage holistic problem-solving rather than focusing on overspecified engineering challenges.
- Behavioral Correctness: Verifiers prioritize functional accuracy over syntactic similarity, rewarding models for producing practical, working solutions.
These features ensure that DeepSWE evaluates models in a manner that aligns with the real-world requirements of software development. By focusing on practical outcomes, DeepSWE provides a more meaningful assessment of an AI model’s capabilities.
Setting a New Standard for AI Coding Models
DeepSWE represents a significant advancement in AI coding model evaluation. By addressing the limitations of traditional benchmarks and focusing on real-world challenges, it provides a comprehensive and practical assessment framework. With its emphasis on contamination-free tasks, diverse repositories, real-world complexity, and reliable verification, DeepSWE sets a new standard for benchmarking AI coding models. It offers valuable insights into their strengths, weaknesses and potential for improvement, paving the way for more effective and reliable AI tools in software development.
Media Credit: Matthew Berman
Filed Under: AI, Top News
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.
Credit: Source link